Quantifying generative AI's sameface syndrome
Click here to send an edit suggestion

Using an open-source facial recognition AI tool on 500 real photos and 500 AI-generated images confirms what we all suspect: AI faces are much less diverse than real faces.
Sending 500 real photos and 500 AI-generated images of female faces through an open-source facial recognition AI tool and then calculating the quartiles of the cosine similarities for every pair of resulting face vectors leads to these results:
I wanted to have some numbers showing whether the similarity of AI-generated faces is imagined or real. I downloaded and selected 500 real photos and 500 AI-generated images, each image a single female face within a relatively narrow age range. These images were sent through an open-source facial recognition AI tool to be mapped to fixed-dimension length-normalized vetors representing the faces in the images. The cosine similarity between 2 such vectors can then be used to estimate the similarity of the corresponding faces.
I then calculated the cosine similarity for each pair of vectors X and Y, with X being from set A and Y being from set B. I calculated the first, second and third quartile of the cosine similarities to characterize the facial similarity of set A and set B. The results:
Do you find it easy to spot AI generated images containing humans? You're not alone. Many people have noticed that all AI-generated faces tend to look very similar to each other. Occasionally that problem is called sameface syndrome or something equivalent and it makes it pretty hard for AI-generated images to pass as real ones. But instead of just guessing, I want to have solid numbers quantifying this problem to find out whether it is imagined or real.
And so I collected a few thousand AI-generated images from places like https://civitai.com/ and also a couple thousand real photos. I deleted from those images all that contain no face or that contain multiple faces and deleted from the AI-generated images all that looked like real people I know. The images contain only faces of women, but both real and AI images contain women of different ethnicities. The age distribution in both sets is the same (as far as I can tell with my eyes) . Of both sets, I selected 500 files at random to be used for the experiment and ignored the rest. I then let an open-source facial recognition AI tool loose on all selected images. This tool maps every image to a fixed-dimension vector, which is supposed to capture all identity-relevant information and none of the identity-irrelevant information. After normalizing these vectors to norm 1, it is possible to calculate the cosine similarity of two of these vectors. A similarity of 1 indicates identical vectors, a similarity of 0 is the expected value of the cosine similarity of two random vectors (and the actual similarity of random vectors is usually close to 0) , a similarity of -1 indicates that the vectors are "opposites". If the facial recognition tool works as intended, similarity 1 should indicate two photos of the face of the same person, but in reality even the face of the same person changes from photo to photo (aging, beard growth, etc.) and so similarity 1 is achievable only for identical images in practice. Values significantly higher than 0 indicate a high similarity of the two corresponding faces, caused by the faces being of the same person, of related persons or of persons otherwise close (e.g. same ethnicity). The tool can be used to easily find photos of the same person in a large pool of images. I tested it, it works.
I then calculated the cosine similarity for each pair of vectors X and Y, with X being from set A and Y being from set B. I calculated the first, second and third quartile (a.k.a. 25th, 50th and 75th percentile) of the cosine similarities to characterize the facial similarity of set A and set B. The second quartile is also known as the median. Set A and B can be identical, in this case the measured similarity is the typical similarity of faces in the set to each other. Here are the results:
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| real photos | real photos | -0.028 | 0.016 | 0.063 |
| AI images | AI images | 0.010 | 0.068 | 0.135 |
| real photos | AI images | -0.033 | 0.010 | 0.055 |
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| real photos | real photos | -0.028 | 0.016 | 0.063 |
| AI images | AI images | 0.010 | 0.068 | 0.135 |
| real photos | AI images | -0.033 | 0.010 | 0.055 |
| only person 0 | only person 0 | 0.476 | 0.562 | 0.617 |
| only person 1 | only person 1 | 0.399 | 0.486 | 0.574 |
| only person 0 | only person 1 | -0.008 | 0.027 | 0.063 |
| real asians | real asians | -0.006 | 0.050 | 0.109 |
| real blacks | real blacks | -0.012 | 0.044 | 0.108 |
| real asians | real blacks | -0.031 | 0.011 | 0.054 |
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| real photos | real photos | -0.028 | 0.016 | 0.063 |
| AI images | AI images | 0.010 | 0.068 | 0.135 |
| real photos | AI images | -0.033 | 0.010 | 0.055 |
| only person 0 | only person 0 | 0.476 | 0.562 | 0.617 |
| only person 1 | only person 1 | 0.399 | 0.486 | 0.574 |
| only person 0 | only person 1 | -0.008 | 0.027 | 0.063 |
| real asians | real asians | -0.006 | 0.050 | 0.109 |
| real blacks | real blacks | -0.012 | 0.044 | 0.108 |
| real asians | real blacks | -0.031 | 0.011 | 0.054 |
To give you a visual representation of the similarity numbers, I have here 3 pairs of faces from the AI generated images. The first pair has a similarity of 0.014, second pair 0.075, third pair 0.137:
Discussion
The AI generated images are indeed much more similar to each other than the real photos are. Given that the similarity of the AI images to the real photos seems to be even lower than the similarity of the real photos to each other, one might surmise that the AI images suffer not just from high similarity, but also from some "unrealness". To make the values more understandable, I also included values calculated from photos of just one person and repeated that for another person and compared these two persons to each other.
I also tested two subsets of the real photos, east asians and dark-skinned persons. Both subsets are more similar to themselves than the real photos in general, no surprise there. But they are still slightly more diverse than the AI images, meaning two randomly selected AI faces are more similar to each other than two randomly selected east asian faces. Also the similarity of real east asian faces to real dark-skinned faces is about the same as the similarity of real faces to AI generated faces.
To give you a visual representation of the similarity numbers, I have here 3 pairs of faces from the AI generated images. The first pair has a similarity of 0.014, second pair 0.075, third pair 0.137:
Discussion
As can be seen in above table, the AI generated images are indeed much more similar to each other according to the facial recognition tool than the real photos are. A median of 0.016 for the real photos is slightly above 0, which shouldn't be surprising given the fact that all photos were of women of a relatively narrow age range. For the AI generated images, the first quartile is already higher than the median of the real photos and the AI median is higher than the real photo's third quartile. Given that the similarity of the AI images to the real photos seems to be even lower than the similarity of the real photos to each other, one might surmise that the AI images suffer not just from high similarity, but also from some "unrealness". Indeed the AI generated faces seem to be overly symmetric and lacking all blemishes like birthmarks, scars, skin problems, etc. (but I do not know whether the facial recognition tool picks up these subtleties) , at least to my eye.
To make the values more understandable, I also included values calculated from photos of just one person and repeated that for another person. This shows that values from 0.4 to 0.6 are typical for photos of the same person. When comparing photos of person 0 to photos of person 1, we again get values similar to the values from all real photos. This just means that person 0 and person 1 are typical representatives of the total set of real photos, neither particularly similar nor particularly dissimilar.
I also tested two subsets of the real photos. In the first subset, only photos of east asians were retained. In the second subset, only photos of dark-skinned persons were retained. Unfortunately the second subset does not contain 500 photos and so is not perfectly comparable to the other sets. But comparing these subsets to themselves and to each other shows once more what the numbers mean. Both subsets are more similar to themselves than the real photos in general, no surprise there. But they are still slightly more diverse than the AI images, meaning two randomly selected AI faces are more similar to each other than two randomly selected east asian faces, at least according to the estimation of the facial recognition tool. Also the similarity of real east asian faces to real dark-skinned faces is about the same as the similarity of real faces to AI generated faces, giving you a better understanding of how different AI generated faces are.
To give you a visual representation of the similarity numbers, I have here 3 pairs of faces from the AI generated images. The first pair has a similarity of 0.014, second pair 0.075, third pair 0.137, chosen to be close to the similarity quartiles of the AI images:

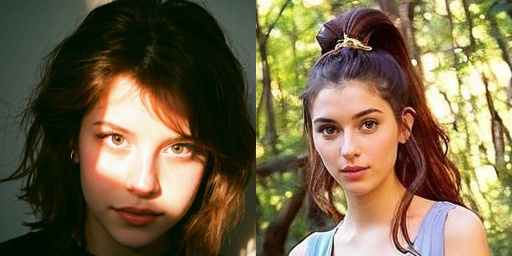

I repeated this with a couple of images from https://thispersondoesnotexist.com/ , because they are GAN-generated , not generated by diffusion-based image generators:
Caveat: The real photos can contain multiple photos of the same person, which would lead to an overestimation of the similarity of the real photos to each other.
I thought that the high facial similarity maybe applies only to diffusion-based image generators, not to GAN-based image generators like StyleGAN2. And so I generated a couple of images on https://thispersondoesnotexist.com/ , and retried it again on those image:
Caveat: The 500 randomly selected real photos can contain multiple photos of the same person, which would lead to an overestimation of the similarity of the real photos to each other. The correct value of the similarity may be lower. No such caveat applies to the AI generated images, which by default generate random faces, having no native capability to produce multiple images of the same person (although additional tools like IP-Adapter can add that capability) . This lack of capability may be obscured in casual observation by the very fact this article tries to examine, i.e. that AI generated faces tend to look very similar to each other, giving the impression that 2 generated images are of the same person, even though the faces are just very similar, not identical.
I thought that the high facial similarity maybe applies only to diffusion-based image generators, not to GAN-based image generators like StyleGAN2. And so I generated a couple of images on https://thispersondoesnotexist.com/ , and retried it again on those image. But despite these images lacking the narrow age range of the other images I tested, the facial recognition tool thinks these GAN-generated images are even more similar to each other:
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| GAN images | GAN images | 0.067 | 0.126 | 0.188 |
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| GAN images | GAN images | 0.067 | 0.126 | 0.188 |
| Set A | Set B | first quartile | second quartile | third quartile |
|---|---|---|---|---|
| GAN images | GAN images | 0.067 | 0.126 | 0.188 |
Caveat: Visually, the GAN images appear much more diverse than the diffusion images, despite what the numbers say.
Caveat: Visually, the GAN-generated images appear much more diverse than the diffusion-based AI-generated, despite what the numbers say. Maybe the facial recognition tool is not yet perfect and thus not able to evaluate the similarity properly. That would also mean that all the conclusions drawn from the above numbers are questionable.
Caveat: I didn't use 500 GAN-generated images, but I tested how the similarity changes with increasing set size and the smaller size can not explain the high similarity. Also, my eyes tell me that the GAN-generated images are much less similar to each other than the diffusion-based AI-generated images are, but maybe the facial recognition picks up some subtle hints that I'm unable to see. I'm also willing to accept that maybe the facial recognition tool is not yet perfect and thus not able to evaluate the similarity properly (i.e. in the way humans would). That would also mean that all the conclusions drawn from the above numbers are questionable.
Click here to send an edit suggestion
Written by the author; Date 06.05.2026; © 2026 spinningsphinx.com
- Mocking
- Sarcasm, e.g. "Homeopathy fans are a really well-educated bunch"
- Statement not to be taken literally, e.g. "There is a trillion reasons not to go there"
- Non-serious/joking statement, e.g. "I'm a meat popsicle"
- Personal opinion, e.g. "I think Alex Jones is an asshole"
- Personal taste, e.g. "I like Star Trek"
- If I remember correctly
- Hypothesis/hypothetical speech, e.g. "Assuming homo oeconomicus, advertisement doesn't work"
- Unsure, e.g. "The universe might be infinite"
- 2 or more synonyms (i.e. not alternatives), e.g. "aubergine or eggplant"
- 2 or more alternatives (i.e. not synonyms), e.g. "left or right"
- A proper name, e.g. "Rome"