A discussion of complexity in Go and other board games
Click here to send an edit suggestion
The difficulty of adapting classical Chess AIs to Go has nothing to do with the number of legal positions in the game, but is instead caused by the apparent impossibility of a fast and accurate hand-crafted evaluation heuristic for Go positions.There is the common misconception that the difficulty of adapting classical Chess AIs to Go is caused by the large number of legal positions in Go or that Go is more complex than Chess due to the large number of legal positions. The reality is that neither Chess nor Go experts ever visit all legal positions, but instead restrict themselves to a small percentage of all reachable positions. Looking at just the visited positions, Go does not appear to be significantly more complex than Chess. 9x9 Go seems slightly simpler than Chess. Theoretical games (like Go without capturing and Chinese counting) offer further evidence that the number of legal positions has little to do with actual complexity. If the number of legal positions were the primary hindrance, 9x9 Go would have been dominated by classical AIs in the mid-90s, but AIs could challenge professional players only around 2010.
The actual reason for the failure of classical AIs in Go is the absence of a fast and accurate hand-crafted evaluation heuristic for Go positions. It is my opinion that such a heuristic likely can't exist due to Semeais and other problems that make drastic evaluation changes due to small board differences extremely common and cause evaluation heuristics to be wrong too often. Random playouts, as used by early Monte Carlo tree search engines, are not fast and contain biases. Learned neural-network-based heuristics are also not fast, not hand-crafted and still have some (though practically irrelevant) biases. Without a good heuristic, a classical/Chess-like AI can not become strong.
Complexity = number of legal positions ?
What's complexity ?
Many people have talked about how Go is the most complex board game or that Go is more complex than Chess and that this supposed complexity is the reason why it took so much longer to produce a Go AI that can defeat the strongest human players. What complexity are they talking about? Usually it's just about the total number of legal positions in the game. By that measure, Go is indeed more complex: Chess has about 5*10^44 legal positions, Go has about 2*10^170 legal positions. But I find it a pretty useless measure to compare the two games.
The first problem for the idea that the number of legal positions indicates the complexity of a game is that neither Chess players nor Go players visit legal positions randomly. Instead, strong players visit only a small fraction of all positions reachable via legal moves. In Chess and 9x9 Go, strong players/engines consider fewer than 2 options per ply on average, in 19x19 Go maybe 4 to 6 options. The number of legal moves in Chess is around 20 on average, in 9x9 Go around 50, in 19x19 Go around 200.
The first problem is that neither Chess players nor Go players visit legal positions randomly. In fact, starting from the standard opening position, only a few lines are played by strong human players. Looking at this 9x9 opening collection , one can determine that a strong AI considers only 13, then 61, then 416, then 1616 positions viable (within half a point of a drawn game). That is 16%, then 0.94%, then 0.16%, then 0.016% of all legal positions within that many moves. Another way to look at this is as a growth rate: 1616 positions within the first 4 moves means around 6.3 options per move (6.34^4 is around 1616) . That is much lower than the number of legal moves, which ranges from 81 for the first move to 78 for the fourth move. In Chess the situation is very similar: The number of opening options considered playable by strong human players is much lower than the number of legal moves.
In 19x19 Go, the number of playable openings is of course larger, but for a more realistic comparison, one could look at middle game positions. Using the same 9x9 opening database, but considering middle game and end game positions, the growth rate of variations seems to be below 1.6 on average. Strong and highly optimized Chess engines also have a growth rate of below 2 in middle game positions at high search depths. For 19x19 Go, numbers are a bit harder to come by, but analyzing a few middle game positions that are close to equal, a strong engine like Katago seems to invest almost all of its effort into 4 to 6 moves on average, indicating a growth rate in that area. That is a little higher than in Chess, but not as high as a comparison of legal moves would suggest. Typical Chess positions have around 20 legal moves, Go middle game positions have around 300 legal moves. I can confidently say that a strong Go player does not consider 15 times as many moves as a Chess player would. If you don't see why this growth rate is relevant: Assuming 6 options per move, it would take 219 moves (half-moves or plies in Chess parlance) to reach the number of legal position in Go, which is already deep in the endgame. To reach the number of legal positions by move 100, the late middle game, would require around 50 options per move, which is far beyond what even amateur players consider. The situation in Chess is similar: At 3 options per move, it would require 94 plies (47 moves) to reach the number of legal positions. Assuming 4 options per move, it could be reached by move 40, but I don't think you'll find many strong Chess players who would argue for 4 good options per move on average. These calculations assume every reached position is unique, so in reality the situation is even worse due to transpositions. Of course the many never visited legal positions are reachable, but only through lines that go through positions that are obviously quite bad for one side.
Theoretical games with large number of legal positions
Theoretical games with large number of legal positions
Theoretical games with a deliberately large number of legal positions offer another angle. Go without capturing and with Chinese counting has an even larger number of legal positions than normal Go, but is clearly a very simple game. Another example is playing two Go games in parallel, but the second board contributes only up to 1 point to the points of the first board, and this adjusted points total decides the game. The number of legal positions of this game is much higher than for normal Go, but although the second board influences the result, it can be ignored without much disadvantage. This second example is not much different in principle from normal Go: The points deciding the game are the sum of all areas of the board and each area has only limited influence on other areas. In fact, in large Go variants like 37x37 or even 99x99, the legal number of positions is much larger than for 19x19, but the game isn't much more complex, because distant areas on a large board have very limited influence (ladder breakers and Kou threats) on each other.
One could also think about theoretical games with a purposely large number of legal positions. One example would be Go with slightly changed rules: All played stones remain on the board (no captures) and the winner is the player who played more stones. The number of legal positions is even higher than in regular Go, around 1.7*10^172. But clearly this game is not complex. In fact, for square boards, one can easily predict the winner based on just the board size. For boards with even board size, the game ends in a draw with optimal play, for odd board sizes the first player wins.
If you think this example is ridiculous, another example: Consider playing two Go games simultaneously, i.e. you play one move each on two boards, then your opponent replies once each on both boards, and so on. The result of this game will be determined by the first board, but the result on the second board contributes up to 1 point to the result of the first board. I.e. if you win the second board, you add 1 point to the points you made on the first board. If you lose the second board, your opponent adds 1 point to the points he made on the first board. If the second board is a draw, the result of the first board is unchanged. The second board clearly has an influence on the outcome of the total game and the complexity of the game on the second board hasn't changed since normal Go rules have been used for each board. But counting the total number of legal positions, around 4*10^340, comparing this to normal Go and concluding this new game is much more complicated than normal Go is obviously not a very sound argument. You could completely ignore the second board and be disadvantaged in the total game by only 1 point. Normal Komi (compensation for the first mover advantage) in Go is 6.5 to 7.5 points, so losing 1 point is not always decisive even in professional play.
This example can easily be extended: Consider playing on 100 boards simultaneously, but boards 2 to 100 each contribute only up to 0.2 points to the total. There is no particular reason to assume the outcomes of boards 2 to 100 are not statistically independent and thus it is appropriate to use the central limit theorem to approximate the probability distribution of points contributed by boards 2 to 100. If each board is a fair game, the expected value is 0 and the standard deviation is around 1 (0.2*sqrt(100*0.5*0.5)) . 95% of results will be within 2 standard deviations of the expected value and so the total game is still determined almost completely by board 1. Completely ignoring boards 2 to 100 is no longer a good strategy, because they could contribute up to 19.8 points. 20 points would be decisive in a professional game, but it is pretty clear that the total outcome is not very dependent on boards 2 to 100 as long as the players try to play properly on all boards.
You probably still think these examples are ridiculous and unrealistic. But normal 19x19 Go is in fact somewhat similar to the last artificial example. The Go board is large and distant areas on the board have a limited influence on each other. The influence is not zero and it changes over the course of the game, but the total outcome is the sum of all points, no matter from which part of the board they come and the outcome on one part of the board is not completely determined by the outcome on another part. That is in fact one important part of strategy in Go: Overwhelmingly winning in one corner does not guarantee a victory in the total game, the opponent still has 3 corners left to try to catch up. I have lost games this way and many other players have as well. Of course in normal Go, all corners are weighted equally, unlike the unfair downweighting of boards 2-100 in the artificial example.
But in principle the artificial example is similar to normal Go: The outcome is the weighted sum of outcomes in different parts of the game. That is not supposed to mean that Go on large boards (like 19x19) is exactly as complicated as Go on small boards (like 9x9) , but it does mean that the complexity of the game probably doesn't scale directly with the board size. Go on really large boards like 37x37 has been played and the normal complexity argument would suggest that this type of game is much more complicated than 19x19 or 9x9 Go because of the large number of legal positions. But the reality is that it is only marginally more complicated, it's just much more tedious. 37x37 is even closer to the artificial example, because of the limited distance over which influence extends on the board. Extending that idea to boards of maybe size 99x99 makes this even clearer: The result in one corner has almost zero influence on the result in a different corner - the influence is limited to ladder breakers and Kou threats. That makes it possible to analyze different parts of the boards separately and add up the results.
I hope that convinces you that the number of legal positions is a bad number for measuring game complexity directly. Number of legal positions and complexity are related, but they are clearly not the same. So why is it that IBM Deep Blue defeated Garry Kasparov, the at that time strongest Chess player in the world, in 1997, but it took almost 20 more years and a very different approach until AlphaGo defeated Lee Sedol in Go and ended the reign of humans as the strongest Go players? Going by number of legal positions alone, one would expect that at least on the 9x9 board (around 10^38 legal positions) , AI would have triumphed over humans much earlier. But in reality, even on 9x9, 1990's AIs could hardly beat strong amateurs, let alone professionals. It is true that in 9x9 Go AI reached strong level much earlier than on 19x19, but it still took until the late 2000s for AI to challenge professionals on 9x9. And it required a new approach: Monte Carlo tree search with random playouts. Classical Go AIs, modeled after strong Chess AIs, suck on 9x9 to this day. You can try GNU Go or Aya and discover that they offer no challenge to experienced amateurs - in the case of Aya not even when starting from a known equal opening position instead of the empty board.
The problem in Go is not the number of legal positions
The problem in Go is not the number of legal positions
The problem with classical/Chess-like AIs is that they require an evaluation heuristic for guessing how good or bad a position is. Chess has a simple, fast and reasonable accurate heuristic, based on assigning values to all Chess men and adding up these values. This heuristic or slight improvements taking more factors into account differs from a proper evaluation a little bit, but differences are rarely extreme, rarely last for the entire game and are most common in tactical positions that are easy to recognize and easy to avoid thanks to Quiescence search.
So what's the deal, are Go AI programmers stupid? No, the problem with classical Chess AIs and their analogues is that they require access to an evaluation heuristic that guesses how good or bad a game position is. The search algorithm (Alpha Beta in this case) can not search arbitrarily deep due to limited computational resources and the leaf positions in the search tree still need some evaluation to be useful. The Horizon effect makes everything beyond the maximum search depth unknowable, which makes it really important to have a good evaluation heuristic. If the evaluation heuristic is consistently wrong, the search can't fix that. Chess is in the comfortable position of having a decent evaluation heuristic. You probably have used it if you ever played Chess seriously: Just assign numbers to every man on the board and add these numbers up, e.g. 1 for pawns, 3 for bishops and knights, 5 for rooks, 9 for queens, 100 for kings, positive for your men, negative for the opposing men.
There are of course many refinements to this basic idea, but almost all Chess evaluation heuristics start from this and even this basic heuristic can produce an AI of moderate strength. Why is this heuristic good? Because it rarely disagrees with a proper evaluation of the position by a lot. Concretely that means that for a large number of randomly chosen positions that strong human players would reach in normal play, if the heuristic indicates a large advantage for one player, a deep search would show an actual advantage for that player in most of the chosen positions. And more importantly: When the game goes on, any discrepancy between heuristic value and true value usually shrinks eventually, i.e. a large error rarely persists until the end of the game. Finally, discrepancies do not occur completely randomly. They usually appear in tactical positions and those are not difficult to identify for strong human players or even AIs. To avoid the known weakness of heuristics in tactical positions, strong Chess AIs use Quiescence search to search for "quiet" positions, i.e. positions where no obvious tactics are possible and the heuristic is likely to produce a decent value.
Even with Quiescence search, the heuristic isn't perfect and its biases can have serious long-term impact on strategy. The described basic heuristic for example completely ignores doubled pawns, king safety and other aspects of the game and strong players can exploit that. But more advanced heuristics are possible and take these weaknesses into account. The remaining weaknesses are hard to exploit (though not impossible to exploit) even for strong human players or other AIs. And on top of all the nice qualities of those heuristics, they are also quick to calculate. Modern highly optimized Chess AIs can evaluate millions of positions per second even on consumer hardware.
No evaluation heuristic for Go
No evaluation heuristic for Go
Comparable heuristics for Go do not exist and arguably can not exist. Attempts at building one have been neither fast nor accurate. The problem is that due to Semeais small changes in a position can lead to an overwhelming change in the evaluation. Semeais occur in the majority of Go games and trying to avoid Semeais leads to suboptimal play. Semeais also can become very large and complicated. Finally, Semeais can persist until almost the end of the game and thus mistakes in evaluating them persist for a long time as well. Even without Semeais, the value of a territorial framework is dependent on whether an invasion there can be successful, which requires deep computation.
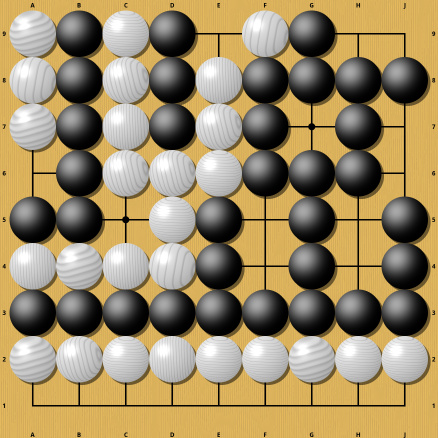
Comparable heuristics for Go do not exist and arguably can not exist. Classical Go engines have tried to build decent heuristics, but they are neither particularly fast nor accurate. The problem is that due to Semeais small changes in a position can lead to an overwhelming change in the evaluation. See the following two positions:
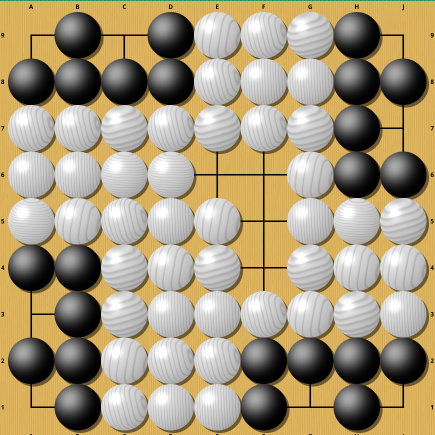
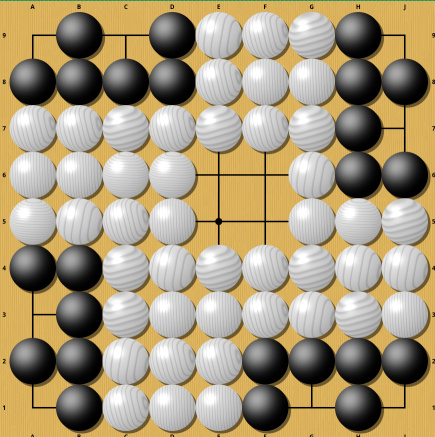
Though not an example of a Semeai, it is an easy to understand position where the movement of a single stone completely changes the result. In one case white wins (thanks to Komi) , in the other, all white stones are dead and black wins. I deliberately chose this example to be easy to understand, so now a somewhat harder example (from Sensei's Library ) :
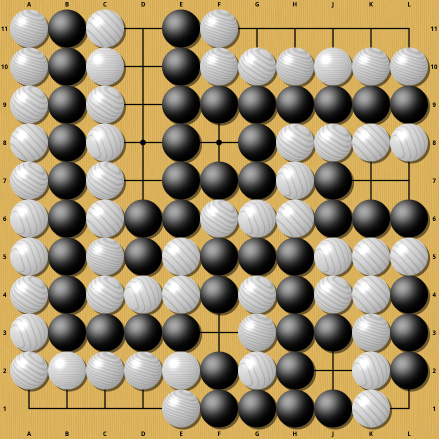
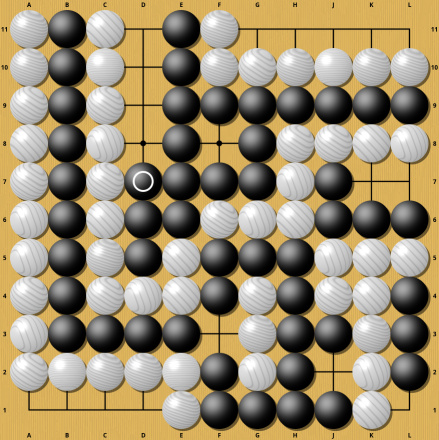
The move seems innocuous, but it completely changes the evaluation from a small white victory to an overwhelming white victory. Understanding why these two are so different clearly requires some computation. A similar example from the same Sensei's Library page:
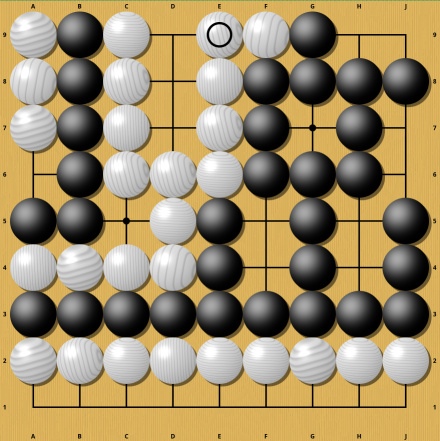
Once again this small change turns a perfectly even game into an overwhelming victory for Black. And once again understanding this requires computation. These two examples are particularly painful for AI, because they make it hard to even just determine whether the game is finished. If the game were almost over and no trickery were involved, these two moves would be completely normal end game moves and would even be necessary with optimal play. The marked moves in the following position would be such cases (saving a stone in Atari, taking away an outside liberty) :
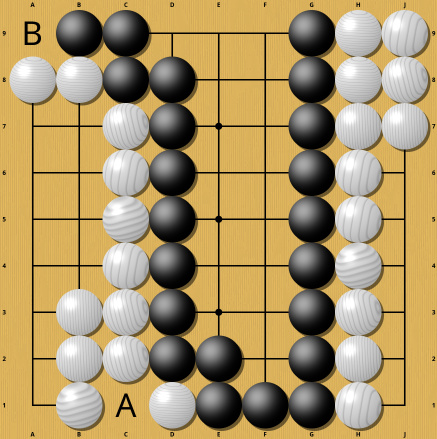
One more example:
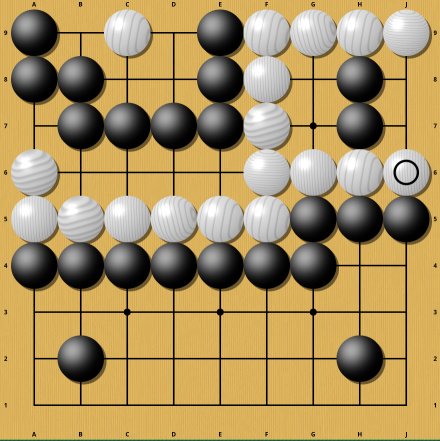
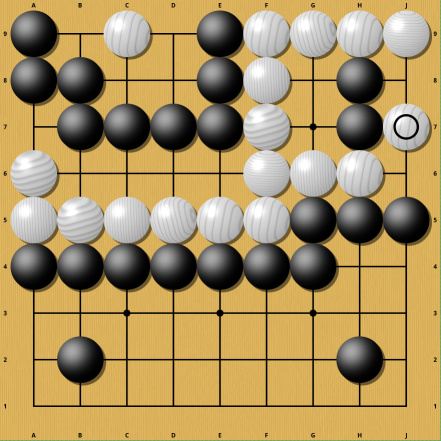
Again this small difference turns a white victory into utter defeat. If you think these examples are artificial and not important for actual play, think again. Semeais are so common that it would be exceptional to see a professional 19x19 game without one. Even if you avoid them, there is still the threat of a Semeai happening in many positions in every game. Desperately trying to avoid Semeais and also all potential Semeais would give the opponent a large advantage and thus is suboptimal play. In other words: Strong players can not completely avoid Semeais. And most Semeais have the potential to become very complicated and grow to encompass a significant part of the board, making the evaluation of that board part entirely dependent on the outcome of the Semeai.
And many of these Semeais also don't go away quickly. Once the Semeai is decided (meaning both players understand what the eventual outcome of the Semeai will be) , it is often suboptimal to keep playing in the Semeai and so it remains on the board until almost the end of the game and sometimes until the very end. Any mistake in the heuristic evaluation of the Semeai thus might persist for a long time, producing a consistently wrong evaluation of the game. That is in fact a hallmark of classical Go engines like GNU Go and Aya and can often be exploited for a large advantage. But it is not just Semeais that cause trouble. Even in positions where nothing much has happened yet, one extra stone can make a huge difference, like in the following example:
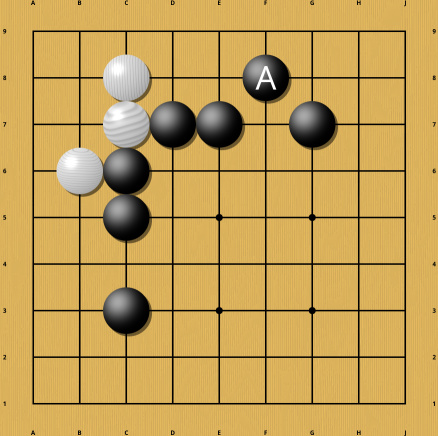
The presence or absence of the marked stone influences whether the white stones in the corner are alive through a not completely trivial sequence of moves and thus influences how many points should be counted for Black or White in this corner. The exact position of this stone is important. If it is too far away, it stops having an influence on the corner. And moving the stone away from the corner does not produce a slow change in the evaluation. It is a step change: beyond a certain distance, the white stones are alive unconditionally. But up to that distance, the attack enabled by the stone can kill the corner unconditionally and without compensation. So guessing just won't do in this case.
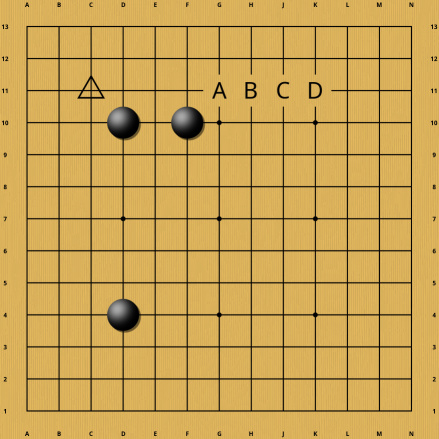
Even when there is no opposing group yet, just potential territory, the precise placement of stones matters. In the following example, Black might consider adding a fourth stone at one of the places marked A to D. Which of these is chosen can have a decisive influence on whether a white corner invasion at the triangle point can survive and thus influences how many points should be counted for Black in that corner. Once again calculation is necessary to make that determination.
The one heuristic that kind of works
The one heuristic that kind of works
Random playouts, as used by early Monte Carlo tree search engines, kind of work. If Chinese rules are used, the game can be played until all dead stones are removed from the board without changing the result, and thus the value of a random continuation (until the end of the game) can be used as an estimate of the value of an unfinished position. Unfortunately, achieving high accuracy requires repeating this process many times, making this heuristic slow. And it is also slightly biased.
Is there any useful and fast evaluation heuristic at all? Yes, there is. But it's applicable only once the game is over. If Chinese rules are used, the game can be played until all dead stones are removed from the board without changing the result (in Japanese rules that is not always possible) . Then a simple heuristic can be used: Consider all stones on the board alive and count points based on the rules. But this heuristic can not be used directly for unfinished games. The original Monte Carlo Go engines (before neural networks) tried to make use of this heuristic by simply finishing the game with a random sequence of legal moves, starting from an unfinished position X, and using the position reached this way as a stand-in for the original position X. The idea is clear: If of the two positions X and Y, X is the better one, random playouts should lead to a frequency distribution of results that is better for X (better means a higher percentage of games is won) than it is for Y. But although this works, it is hardly efficient. Many random playouts have to be played and then counted before a usable value appears. It is like tossing a coin to find out whether the coin is fair. Tossing once is not going to help you much. In typical cases, even 100 coin tosses would not always allow you to make a clear determination of fairness.
To illustrate how dire the situation is: Even professional players have a standard deviation of over 5 points starting from the empty board, i.e. the distribution of point results of non-resigned professional games has a standard deviation of >5. And clearly professionals don't play randomly. If you wanted to distinguish two positions that differ by only one point in evaluation, you would need around 200 random professional games starting from that position to reach 95% certainty. If you did it without professionals, just completely randomly, you would need around 20000 random playouts to reach that certainty, assuming random playouts from the empty board have a standard deviation of 50. So, even though that heuristic kind of works, it is really slow compared to what is available in Chess.
But random playouts are not only slow, they are also biased. The above-mentioned Go positions illustrating difficult cases for an evaluation heuristic contain Sekis and Sekis would be problematic for random playouts. Playing any move in a Seki is a costly mistake, but random playouts would play everywhere they can until everything is captured. Even with some restrictions like not filling your own one-point-eyes and avoiding to play in a few commonly occurring Sekis would not stop the random playout from playing in uncommon Sekis. And unfortunately there are infinitely many Sekis, so it's just not possible to memorize all of them. That means there will definitely be cases where random playouts will lead to a consistently wrong evaluation (namely that the Seki dies) . Monte Carlo Tree Search can fix some of that, but the tree search would still converge very slowly to the true value in some positions, because it has to constantly fight against the subtle incorrectness of random playouts. Once a player has figured out this flaw, it can be exploited by deliberately constructing such problematic Sekis. But even without any bias, completely random playouts simply converge too slowly to the true evaluation of a position to produce a professional level Go AI.

Do you get the feeling I'm arguing that strong Go AIs should be impossible in general? That would be something that is clearly contradicted by the existence of AlphaGo, Leela Zero and Katago. But these AIs do not use an evaluation heuristic in the same sense as is used in classical Chess engines. AlphaGo and the like use a learned neural-network-based evaluation heuristic. And in contrast to Chess, this is hardly fast: The AlphaZero publication mentions that AlphaZero evaluates only 60000 positions per second compared with Stockfish's (a classical Chess engine) 60 million positions per second. That is despite specialized hardware that is highly optimized for executing artificial neural network inference, while Stockfish ran on commodity hardware (compare to IBM's Deep Blue, which used specialized hardware to achieve 200 million evaluations per second 2 decades earlier) . AlphaZero defeated Stockfish, clearly showing that a learned evaluation heuristic can be superior to one handcrafted by humans. But these learned heuristics needed a completely different approach (neural networks and reinforcement learning) , specialized hardware that didn't exist in 1997, produce gigantic and inscrutable code (millions of parameters) and - in the case of Go - still contain catastrophic biases. The following two positions are evaluated consistently incorrectly by Katago (but to be fair, GNU Go and Aya fail as well in the first position) :

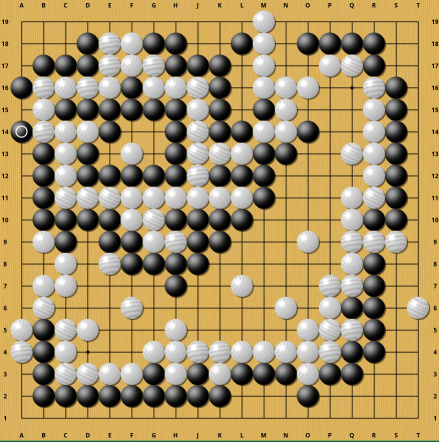
In the first position, the game is equal (assuming Chinese rules and 7.5 Komi) and the winner is determined by who plays first. Katago on the other hand does not converge to a realistic evaluation even after a lot of computation and its evaluation fluctuates a lot, despite the game almost being over. In the second position (thanks to this ) , White has already lost the game by a wide margin, but Katago thinks White is far ahead and does not figure out the problem even after minutes of computation. These are not examples of extremely complicated positions where the failure is caused by a shallow search, in both cases Katago's evaluation heuristic trips over one of its biases. Katago probably never encountered similar positions during its training and thus fails to generalize its knowledge to these positions. My suspicion is that in the first case, Katago just can't handle large Semeais with lots of shared liberties, because there are millions of sequences for finishing the Semeai and all of them are quite long. On top of that, it is easy to make a mistake in that Semeai if one is unfamiliar with it. In the second case, the problem might come from the fact that White's group has a circular topology, so maybe Katago's neural network goes around that circle multiple times and thus counts its liberties more than once. All of that is just speculation and I'm sure the Katago authors have already figured out what's wrong and how to fix it. But these examples serve to demonstrate that even Go AIs with superhuman strength still have blind spots.
Conclusion
Conclusion
A hand-crafted, simple, fast, reasonably accurate and unbiased evaluation heuristic for Go will probably never exist and thus prevents classical Go engines from ever achieving superhuman strength. Learned heuristics are not fast, not simple, not handcrafted, not easy to understand, not completely free of bias, but at least accurate enough to serve their primary purpose in Monte Carlo Tree Search. In any case, the problem is not the number of legal positions.
And with that I hope I have demonstrated convincingly that a hand-crafted, simple, fast, reasonably accurate and unbiased evaluation heuristic for Go will probably never exist and thus prevents classical Go engines from ever achieving superhuman strength. The best we can hope for are learned heuristics that are not fast, not simple, not handcrafted, not easy to understand, not completely free of bias, but at least accurate enough to serve their primary purpose in Monte Carlo Tree Search. In the accuracy department, Katago has achieved a resounding success: Almost all positions reached in human games are evaluated with an accuracy that surpasses strong amateurs without any tree search and surpasses professional players with tree search and a little bit of time.
In any case, the problem is not the number of legal positions.
Click here to send an edit suggestion
Written by the author; Date 27.01.2026; Updated 17.02.2026; © 2026 spinningsphinx.com
Written by the author; Date 27.01.2026; Updated 17.02.2026; © 2026 spinningsphinx.com
Written by the author; Date 27.01.2026; Updated 17.02.2026; © 2026 spinningsphinx.com
Written by the author; Date 27.01.2026; Updated 17.02.2026; © 2026 spinningsphinx.com
- Mocking
- Sarcasm, e.g. "Homeopathy fans are a really well-educated bunch"
- Statement not to be taken literally, e.g. "There is a trillion reasons not to go there"
- Non-serious/joking statement, e.g. "I'm a meat popsicle"
- Personal opinion, e.g. "I think Alex Jones is an asshole"
- Personal taste, e.g. "I like Star Trek"
- If I remember correctly
- Hypothesis/hypothetical speech, e.g. "Assuming homo oeconomicus, advertisement doesn't work"
- Unsure, e.g. "The universe might be infinite"
- 2 or more synonyms (i.e. not alternatives), e.g. "aubergine or eggplant"
- 2 or more alternatives (i.e. not synonyms), e.g. "left or right"
- A proper name, e.g. "Rome"